


下载elasticsearch-7.17.16-linux-x86_64.tar
创建cd /usr/local/soft/文件夹
进入/usr/local/soft/文件夹
cd /usr/local/soft/
把下载好的elasticsearch-7.17.16-linux-x86_64.tar复制进来
解压elasticsearch-7.17.16-linux-x86_64.tar文件
tar -zxvf elasticsearch-7.17.16-linux-x86_64.tar.gz配置环境变量
vim /etc/profile如果/etc/bashrc文件不可编辑,需要修改为可编辑
chmod -v u+w /etc/environment在最后一行加上
export ES_JAVA_HOME=/usr/local/soft/elasticsearch-7.17.16/jdk注意事项:
生效时间:新开终端生效,或者手动
source /etc/environment生效生效期限:永久有效
生效范围:对所有用户有效
进入/usr/local/soft/elasticsearch-7.17.16
cd /usr/local/soft/elasticsearch-7.17.16修改主配置文件 elasticsearch.yml:
vim config/elasticsearch.yml# ES开启远程访问
network.host: 0.0.0.0
# 设置主节点(一个集群设一个就行)
node.master: true
node.name: node-1
# 配置发现设置
discovery.seed_hosts: 192.168.49.100 # "127.0.0.1"可以改为外网ip
cluster.initial_master_nodes: ["node-1"]
# 跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
# 允许请求头携带密码访问
http.cors.allow-headers: Authorization
# 开启密码访问
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
ingest.geoip.downloader.enabled: false修改JVM配置:
修改config/jvm.options配置文件,调整JVM堆内存大小
vim config/jvm.options输入:
-Xms128m
-Xmx128m注意:
启动 elasticsearch 不能使用 root 用户
创建新用户:
sudo useradd -m -s /bin/bash admin设置密码:
sudo passwd admin添加该用户到管理员组:
sudo usermod -aG root admin切换到root用户,赋予组对该目录及其子目录的读写权
chmod -R g+rwx /usr/local/soft/elasticsearch-7.17.16启动:
su admin
在/usr/local/soft/elasticsearch-7.17.16目录下
cd /usr/local/soft/elasticsearch-7.17.16
bin/elasticsearch后台启动
bin/elasticsearch -d常见启动报错:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
编辑/etc/sysctl.conf文件,在最后添加一行
vm.max_map_count=262144重启
sudo sysctl -pthe default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
在 elasticsearch.yml 配置文件中,添加如下内容:
discovery.seed_hosts: ["127.0.0.1"] # "127.0.0.1"可以改为外网ip
cluster.initial_master_nodes: ["node-1"]设置密码:
执行设置用户名和密码的命令,这里需要为4个用户分别设置密码,elastic, kibana, logstash_system, beats_system
在启动了ES后设置,用root用户就可以了
bin/elasticsearch-setup-passwords interactive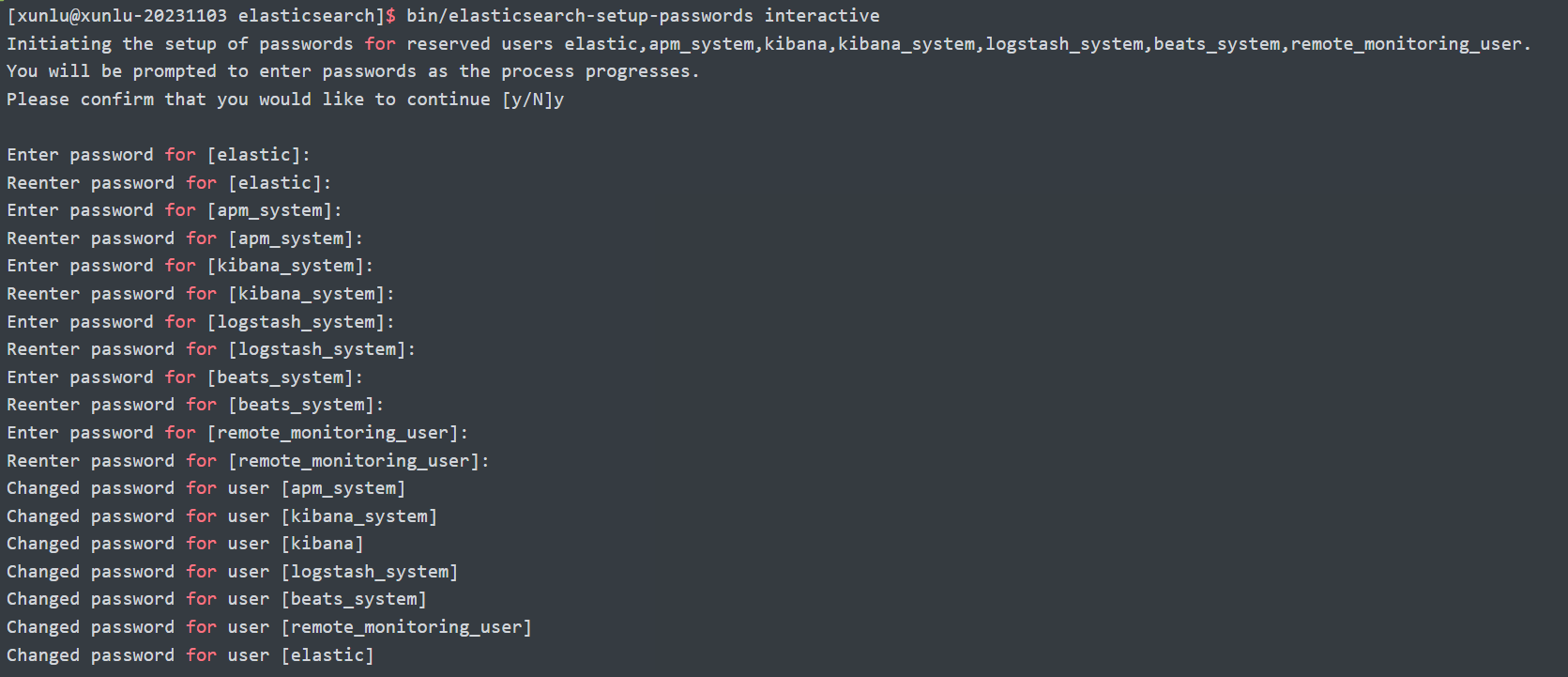
其中,用户权限分别如下:
elastic 账号:拥有 superuser 角色,是内置的超级用户。
kibana 账号:拥有 kibana_system 角色,用户 kibana 用来连接 elasticsearch 并与之通信。Kibana 服务器以该用户身份提交请求以访问集群监视 API 和 .kibana 索引。不能访问 index。
logstash_system 账号:拥有 logstash_system 角色。用户 Logstash 在 Elasticsearch 中存储监控信息时使用。
修改密码命令如下(新密码为123456):
curl -H "Content-Type:application/json" -XPOST -u elastic 'http://127.0.0.1:9200/_xpack/security/user/elastic/_password' -d '{ "password" : "123456" }'ElasticSearch设置用户名密码之后,不能再直接使用ElasticSearch head 访问,可以在查询等API上加上用户等参数:
curl -XGET --user user:passwd 'http://XXXX:9200/XX/XXX'如果忘记密码:
修改elasticsearch.yml 配置,将身份验证相关配置屏蔽掉;
重启ES,查看下索引,发现多了一个.security-7索引,将其删除
curl -XDELETE 'http://127.0.0.1:9200/.security-7'3.到此就回到ES没有设置密码的阶段了,如果想重新设置密码,请从头开始
安全并正确地关闭或重启Elasticsearch:
elasticsearch本身具有高可用性,可以做到停机不停服务,在重启elasticsearch后可能存在数据丢失,或者是“启动ES后,怎么一直有大量的数据在迁移?”
原因有两点:
ES中的数据不是实时写入磁盘的。
数据进入ES后先进入data buffer segment和transientLog这两个buffer,(此处又涉及到数据防丢失的机制)然后进入操作系统文件系统缓存的数据段,最后再特定时机(两个条件,一个是segment到达容量,一个是到达refresh时间间隔)下才刷入磁盘。即在内存中有很多数据是没写入磁盘的。
ES的分片自动分配迁移机制。当集群发现经过一分钟后(index.unassigned.node_left.delayed_timeout参数设置)还连接不上某个节点,就会把集群内的数据重新进行分布,即使后来节点重新连接上,原来的数据因为重新分布也无效了。
设置集群重新分配的类型,使用cluster.routing.allocation.enable设置选项。
启用或禁用分片重新分配的类型:
all- (默认) 允许所有类型分片重新分配primaries- 只允许主分片重新分配new_primaries- 只允许新索引的主分片重新分配none- 所有索引的任何类型分片不被允许重新分配
# 1 关闭分片分配
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
# 2 停止索引并执行同步刷新
POST _flush/synced
# 3 暂时停止机器学习和数据仓库相关任务
POST /_ml/set_upgrade_mode?enabled=true&pretty
# 4 关闭所有节点
# 查看进程pid
ps -ef|grep elasticsearch
# 杀死进程及其子进程
kill -SIGTERM 2510857 2510909
# 或者直接根据进程名杀死所有进程
pkill -f elasticsearch
# 5 重启
bin/elasticsearch -d
# 6 启用分片自动分布
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}注:开放9200端口
查看ES服务端状态:
curl -XGET http://114.514.19.19:9200
curl -XGET http://114.514.19.19:9200/_cluster/health